这是一个对HTML进行分析的快速实时的解析器,可以通过DOM或CSS选择器来查找,提取数据。
下面例子展示此解析器的用法,例子还用到了上方提到的Java采集引擎。
package cfw.test; import cfw.html.TagSearchRange; import cfw.html.HtmlParser; import cfw.html.HtmlTag; import cfw.http.ResponseResult; import cfw.http.UserAgentPack; import cfw.http.WebClient; import cfw.http.WebRequest; import cfw.model.FinancialNewsListModel; import com.alibaba.fastjson.JSONArray; import com.sun.jndi.toolkit.url.Uri; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class HtmlParserTest { public static void main(String[] args) { // 【新浪财经要闻文章列表】抓取 List<FinancialNewsListModel> sinaNews = crawlSinaFinancialNewsList(); System.out.println(String.format("【新浪财经-要闻列表页】抓取到%s个文章列表", sinaNews.size())); String json = JSONArray.toJSON(sinaNews).toString(); System.out.println(json); // 【凤凰财经文章列表】抓取 List<FinancialNewsListModel> ifengNews = crawlIFengFinancialNewsList(); System.out.println(String.format("【凤凰财经-文章列表页】抓取到%s个文章列表", ifengNews.size())); String json2 = JSONArray.toJSON(ifengNews).toString(); System.out.println(json2); } /** * 【新浪财经要闻文章列表】抓取 * * @return */ private static List<FinancialNewsListModel> crawlSinaFinancialNewsList() { /* 抓取地址: http://finance.sina.com.cn/ */ List<FinancialNewsListModel> fnews = new ArrayList<FinancialNewsListModel>(); try { String url = "http://finance.sina.com.cn/"; WebRequest req = new WebRequest(); req.setUrl(url); req.setMethod("GET"); req.setUserAgent(UserAgentPack.getUserAgentRandom()); Map<String, String> dic = new HashMap<String, String>(); dic.put("Upgrade-Insecure-Requests", "1"); dic.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"); dic.put("Accept-Encoding", "gzip, deflate"); dic.put("Accept-Language", "zh-CN,zh;q=0.8,en;q=0.6"); req.setSpecialHeadCollection(dic); ResponseResult sr = WebClient.download(req); String html = sr.getResponseHtmlStr(); HtmlParser parser = new HtmlParser(html); HtmlTag htmlTag = parser.parse(); // 要闻 HtmlTag finTag = htmlTag.getElementById("fin_tabs0_c0"); List<HtmlTag> aTags = finTag.getElementsByTagName("a"); for (HtmlTag aTag : aTags) { FinancialNewsListModel list = new FinancialNewsListModel(); list.setArticalUrl(aTag.getAttribute("href")); list.setArticalTitle(aTag.getValue()); Uri uri = new Uri(list.getArticalUrl()); String[] strs = uri.getPath().split("/"); if (strs.length > 1) { list.setArticalMD("sina-" + strs[strs.length - 1].replace(".html", "").replace(".shtml", "")); fnews.add(list); } } } catch (Exception ex) { System.out.println("【新浪财经-要闻列表页】抓取失败" + ex.getMessage()); } return fnews; } /** * 【凤凰财经文章列表】抓取 * * @return */ private static List<FinancialNewsListModel> crawlIFengFinancialNewsList() { /* 抓取地址: http://finance.ifeng.com/ */ List<FinancialNewsListModel> fnews = new ArrayList<>(); try { String url = "http://finance.ifeng.com/"; WebRequest req = new WebRequest(); req.setUrl(url); req.setMethod("GET"); req.setUserAgent(UserAgentPack.getUserAgentRandom()); Map<String, String> dic = new HashMap<>(); dic.put("Upgrade-Insecure-Requests", "1"); dic.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"); dic.put("Accept-Encoding", "gzip, deflate"); dic.put("Accept-Language", "zh-CN,zh;q=0.8,en;q=0.6"); req.setSpecialHeadCollection(dic); ResponseResult sr = WebClient.download(req); String html = sr.getResponseHtmlStr(); HtmlParser parser = new HtmlParser(html); HtmlTag htmlTag = parser.parse(); HtmlTag listTag = htmlTag.search(t -> t.getAttribute("class").equals("list-tab"), TagSearchRange.AllElements).get(0); List<HtmlTag> divTags = listTag.search(s -> s.getAttribute("class").equals("list_L z20 clearfix"), TagSearchRange.AllElements); for (HtmlTag divTag : divTags) { HtmlTag list_textTag = divTag.search(d -> d.getAttribute("class").equals("list_text"), TagSearchRange.AllElements).get(0); HtmlTag aTag = list_textTag.getElementsByTagName("a").get(0); FinancialNewsListModel list = new FinancialNewsListModel(); list.setArticalUrl(aTag.getAttribute("href")); list.setArticalTitle(aTag.getValue()); Uri uri = new Uri(list.getArticalUrl()); String[] strs = uri.getPath().split("/"); list.setArticalMD("ifeng-" + strs[strs.length - 1].replace(".html", "").replace(".shtml", "")); fnews.add(list); } } catch (Exception ex) { System.out.println("【凤凰财经-文章列表页】抓取失败" + ex.getMessage()); } return fnews; } }
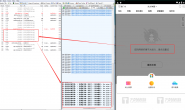
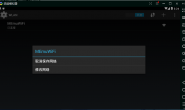
运行结果如下:

最后
转载请注明:深圳彦祖 » Java版HTML解析器